I’ve always wondered how Spotify recommends tracks and albums to their users. After some digging, I discovered that they use a multitude of machine learning models. One of them being collaborative filtering and a model built on song features. I set out to try and build my own small recommendation system, which can be found here on GitHub.
However, due to the lack of data sets available that can be used for collaborative filtering, I checked if it is feasible to fit a model on song features. Soon I found a huge data set that included features like danceability, energy, key, acousticness, etc. on 1.2 million tracks. You can find it here. With the data at hand, I quickly discovered another pitfall. How can I make new predictions for tracks that are not in the data set? Somehow, I’d have to be able to calculate all the features like danceability and energy. After another search, I found that Spotify trained models to extract these features from a track’s spectrogram, which meant that I’d have to build these models first. Hence, I dismissed all previous ideas and came up with my own approach.
Approach
I used the 1.2 million Spotify song data set and performed dimensionality reduction on the features. UMAP was the algorithm that I applied. The application itself is quite simple, after a preprocessing step, UMAP reduced the data set to 2 dimensions (this is the script). The resulting embedding is the backbone for the recommender. The approach for recommending a song is quite simple. Based on an input song, the track with the lowest euclidian distance to the input is found. The distance is calculated using the embedding, which is visualized below. The embedding is colored by the song key. Remarkably, the data clusters nicely.
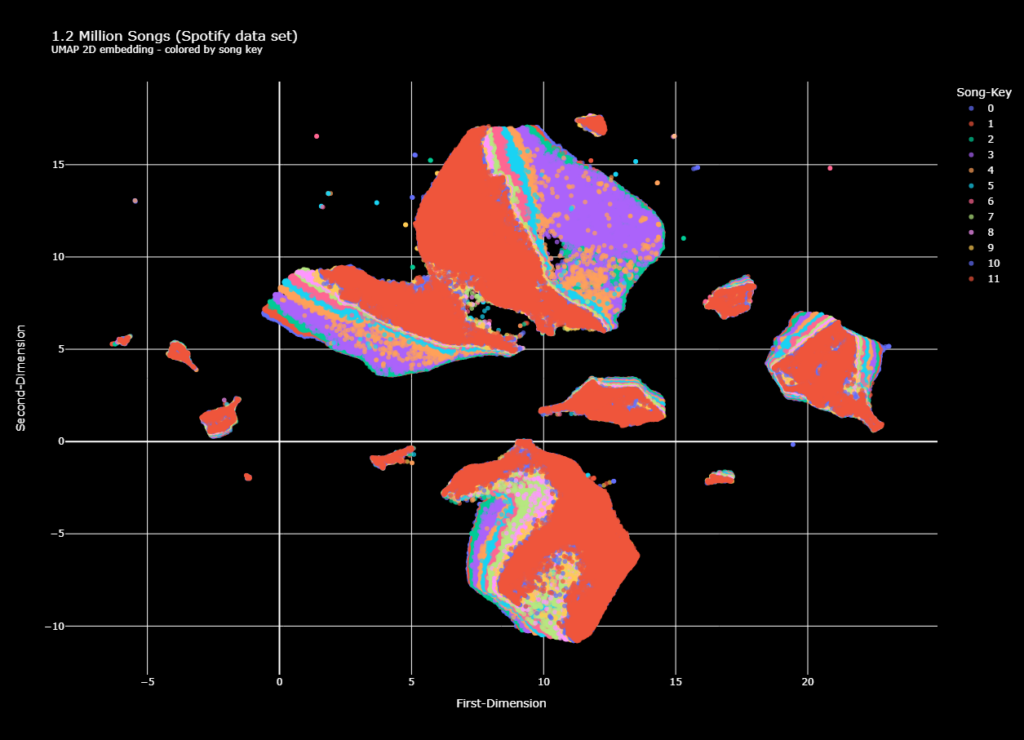
Admittedly, my approach has some downsides as well. The biggest, being the inability to get a recommendation based on an input song that wasn’t in the initial data set. Nevertheless, the given data set is quite diverse (genre-wise) and should cover a large portion of the input tracks.
API
The easiest way to use the recommender is through an API. The API has two endpoints, /random and /recommend. The latter one requires an input track and returns the recommendation. For example, given Dire Strait’s input track Money For Nothing, the song
{
"spotify_id": "52lOxcQq1cQYPeHAucCONP",
"name": "I Was Told - Acoustic",
"album": "And Then It Got Ugly",
"artists": "['Rhino Bucket']"
} was recommended. The endpoint /random simply returns a random track from the data set. In order to set up the API, a Dockerfile is provided. Alternatively, the recommender can be used directly, without spinning up the API. Here’s another small example on how to use the recommender without the API:
from recommender import TrackRecommender
rec = TrackRecommender()
# get the Spotify id for Dire Strait's - Money For Nothing
money = rec.resolve_song_name_to_id(song_name="Money For Nothing")
# >>> money
# '6Kk9alrXcIuPXQnsQVvGWM'
# get a recommendation
rec_track = rec.recommend(song_id=money)
# >>> rec_track
# {
# "spotify_id": "52lOxcQq1cQYPeHAucCONP",
# "name": "I Was Told - Acoustic",
# "album": "And Then It Got Ugly",
# "artists": "['Rhino Bucket']"
# } Regardless of whether you use the API or the recommender directly, the UMAP embedded data is included in the repo as well. Hence, there’s no need to fit the UMAP and the recommender can be used straight away.
With the recommendation system available through an API, one can build a lot of things around that. I’ll use the recommender for a web app that I’ve been planning to do for quite some time now. 🎸
-Jakob