Want to know how you can set up your local ChatGPT without any coding involved? This guide will walk you through on how to get up and running, including a great UI and a lot of customizability for your own Large Langue Model (LLM).
Following this guide will take roughly 10 minutes and you will end up with the following nice modern GUI for your local LLM:
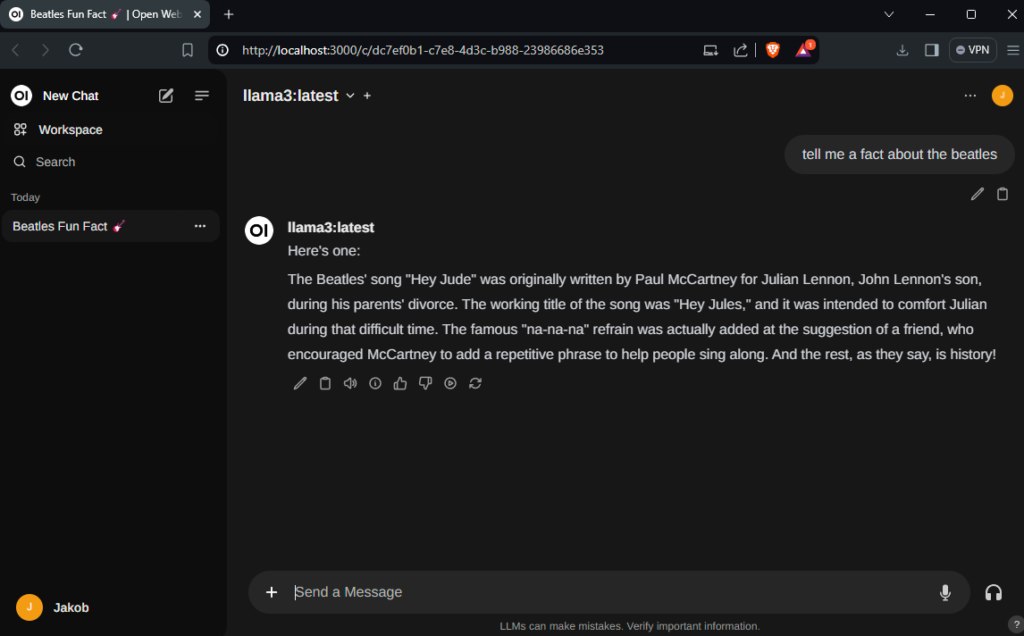
Let’s get started
As a prerequisite you simply need Docker installed and a single command. Without further redo, here’s the command, if you have a GPU:
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaFor CPU use:
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaSimply put, both commands will install ollama and Open WebUI within a docker container. Ollama is the backbone, where we’ll also pull our models from. Open WebUI is the ‘ChatGPT like’ user interface (just with even more features!). What’s really convenient, if you chose the GPU option, the docker container will automatically utilize your GPU which will save you a lot of computational time. To access the UI, navigate to
localhost:3000You’ll be greeted by a sign-up form. Simply, sign-up, but note, that the first account created, will be the admin.
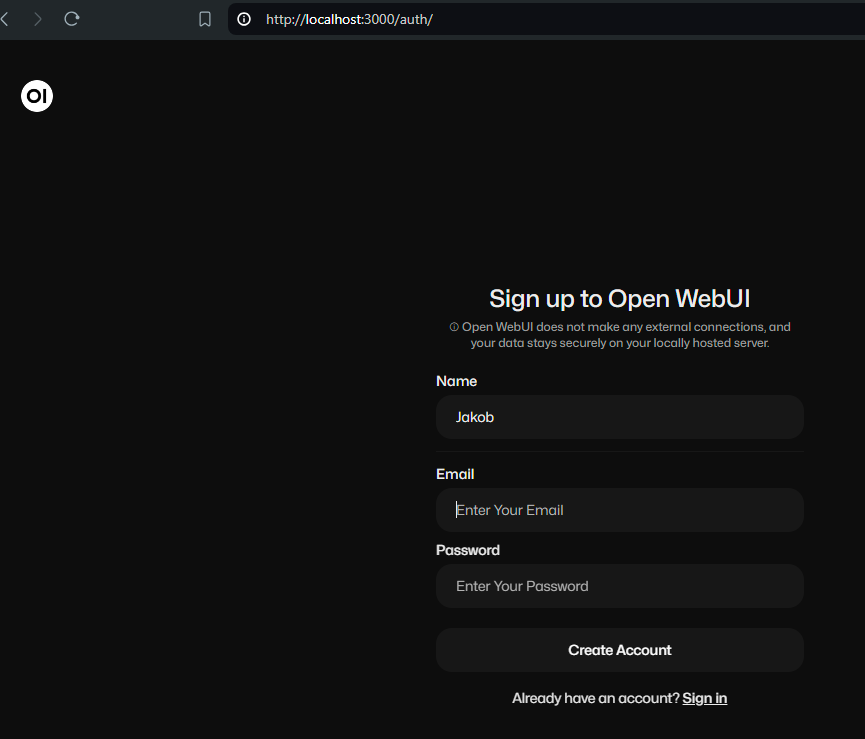
After signing-up you’ll be greeted by the starting screen and the chat interface. However, as there are no models pre-loaded, head to your user icon in the lower left corner -> select Admin Panel -> Settings -> Model. Within the “Pull a model from Ollama.com” textbox, type llama3 to download the latest llama model.
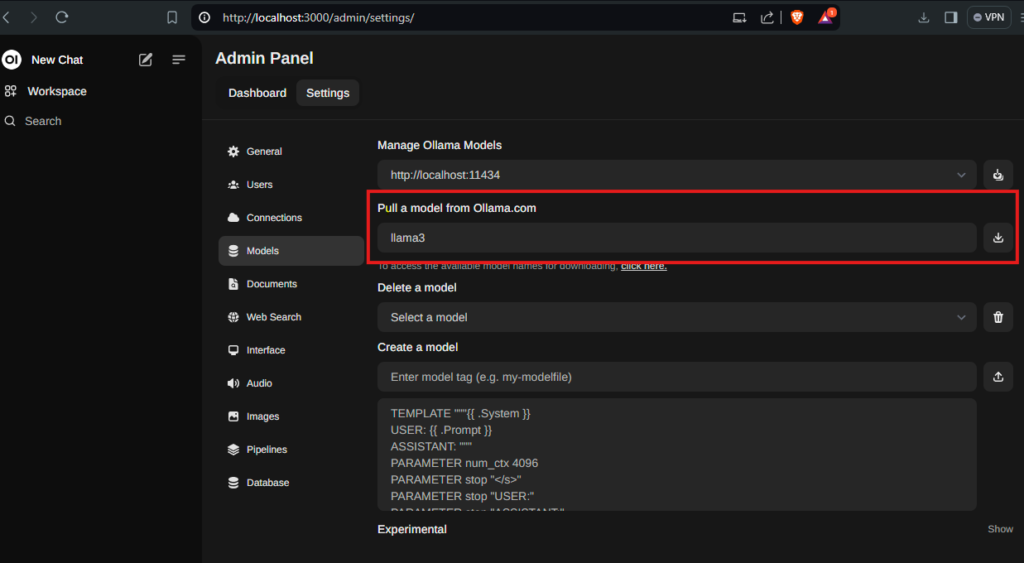
llama3 is a good starting point as it supports multiple languages and is quite proficient at coding. If you prefer another model, you can have a look the list of available ollama models here. Some suggestions are:
- llava – Multi-modal model, e.g., able to explain pictures.
- codellama – Llama model fine-tuned for coding tasks.
Depending on your choice, downloading the model might take some time as all the models have a couple of gigabytes.
Now you’re ready to chat with your own local LLM. Stay tuned, for tips on customization, providing context with your own documents and creating your own personalized model.